
 by
by Nothing has the potential to ruin a product or even an organization more than software instability. Most of us get excited by focusing on developing new features or services and we neglect the operation thereof. Agile methodologies mostly focus on product development. In large organisations with hundreds of systems this is not enough. You need more than just a methodology achieve resilience. This is where Engineering Practices come in.
Mike Murphy is undoubtedly an expert when it comes to resilience. An expert for me is someone who has the scars of years of sleepless nights and ruined weekends because of a system being down AND and who has the theoretical background on the subject matter. Mike is such a person
In this second part of three articles we will focus on the engineering practises that helps making systems more reliable. Consider it a cheat sheet to improve your engineering.We covered the causes of system instability in Towards System Resilience (Part 1). Over to Mike
Engineering Practices
Over the last 30 years, software has transformed from monolithic to highly distributed, and evolved to service-oriented (SOA) and micro-service architectures, all in an effort to reduce the number of points of change or failure, and improve the time-to-value when new functionality is implemented. Engineering disciplines have undergone significant change over this time too and the methods, techniques and practices prominent today are geared towards producing reliable, scalable and resilient systems.
Agile Software Development
Agile Software Development is an umbrella term for a set of methods and practices based on the values and principles expressed in the Agile Manifesto. Solutions evolve through collaboration between self-organizing, cross-functional teams utilizing the appropriate practices for their context.
The term "Agile" was applied to this collection of methodologies in early 2001 when 17 software development practitioners gathered in Snowbird, Utah to discuss their shared ideas and various approaches to software development. This joint collection of values and principles was expressed in the Manifesto for Agile Software Development and the corresponding twelve principles (www.agilemanifesto.org).
The principles behind the Agile Manifesto are:
- Our highest priority is to satisfy the customer through early and continuous delivery of valuable software.
- Welcome changing requirements, even late in development. Agile processes harness change for the customer's competitive advantage.
- Deliver working software frequently, from a couple of weeks to a couple of months, with a preference to the shorter timescale.
- Business people and developers must work together daily throughout the project.
- Build projects around motivated individuals. Give them the environment and support they need, and trust them to get the job done.
- The most efficient and effective method of conveying information to and within a development team is face-to-face conversation.
- Working software is the primary measure of progress.
- Agile processes promote sustainable development. The sponsors, developers, and users should be able to maintain a constant pace indefinitely.
- Continuous attention to technical excellence and good design enhances agility.
- Simplicity--the art of maximizing the amount of work not done--is essential.
- The best architectures, requirements, and designs emerge from self-organizing teams.
At regular intervals, the team reflects on how to become more effective, then tunes and adjusts its behavior accordingly.
Using iterative software development cycles that incrementally build the system is one of the primary principles of agile software development.
A rapid, iterative development cycle provides an ideal opportunity to inject proper testing practices—both manual and automated—such as code reviews, continuous integration, and automated unit and regression testing. Teams working this way can test quality up front and therefore correct errors and defects early in the development cycle, when it costs the least. The marriage of the agile principle of rapid iteration, proper agile testing, and design practices helps yield higher quality software applications and sustained quality over time.
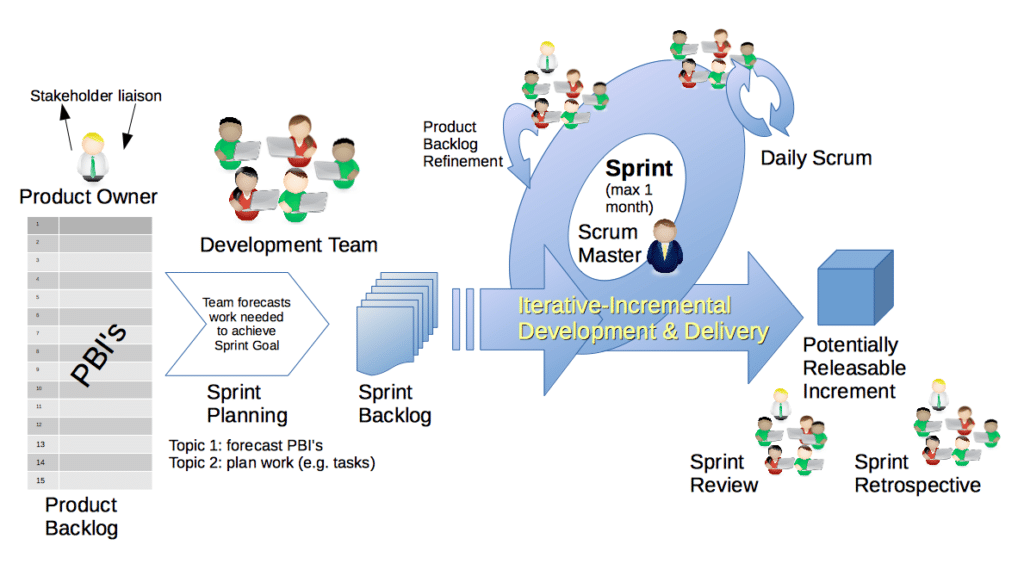
Scrum is a great implementation of an Agile methodology.
Automation
Whilst not strictly a practice or method, automation is the next critical step in IT maturity—building trust into IT systems and enabling innovation of new capabilities. Automation lowers operational overhead and frees up time for engineers to proactively assess and improve the services they support. Highly resilient systems depend on automation. Manual operations are prone to error, offer slow response times and can eat up costly man-hours. This actually hampers the overall efficiency and effectiveness of IT operations, not improves it. Historically, the process of manually developing and deploying software to production has been archaic at best. Manual or no code analysis allows technical issues to accumulate. Manual testing often misses regressions, manual infrastructure management introduces anomalies in environment configuration, and manual deployments introduce risks. In short, manual practices cost time and money.
However, automation itself comes with risk so the question that always needs to be asked is “When is it safe to automate?”. Implementers of the automation have a moral imperative to create automation that is serviceable, instrumented, and documented.
Continuous Delivery
The emerging process for developing and deploying applications of high quality is one that is highly automated, executing continuously, and covers the entire development process, from modifying code through testing to deployment. This process is called continuous delivery, and automation is a key component of a mature continuous delivery process.
Continuous delivery provides confidence because the processes are executed efficiently and consistently every time. Ongoing improvements to the continuous delivery process enable business agility while maintaining stability. Rather than using an assembly line of skilled engineers to manually develop, test, and deploy code, continuous delivery uses automation to continually perform code analysis, unit tests, integration tests, provision servers, configure them, and manage dependencies (infrastructure automation).
An important component of continuous delivery is continuous integration. Continuous Integration is a software development practice where members of a team integrate their work frequently. Each integration is verified by an automated build (including test) to detect integration errors as quickly as possible. Projects with Continuous Integration tend to have dramatically less bugs, both in production and in process and hence applications developed using continuous integration are more stable.
Canary releases
Canary release is a technique to reduce the risk of introducing a new software version in production by slowly rolling out the change to a small subset of users before rolling it out to the entire infrastructure and making it available to everybody. It is an application of parallel change, where the migrate phase lasts until all the users have been routed to the new version. At this point the old infrastructure can be decommissioned. The rollback strategy if any problems are detected with the new version is to reroute users back to the old version until the problem has been fixed.
A benefit of using canary releases is the ability to do capacity testing of the new version in a production environment with a safe rollback strategy if issues are found. Instability caused by failed implementations is greatly reduced through the use of Canary releases. The practice of Canary releases is generally used for Internet facing applications e.g., Internet Banking sites.

Blue-Green deployment
One of the challenges with automating software deployments is taking software from the final stage of testing to live production. This should be done as quickly as possible in order to minimize downtime. The blue-green deployment approach does this by ensuring there are two production environments, as identical as possible. At any time one of them (e.g., Blue) is live. Prior to release, final testing is done in the green environment. Once the software is working in the green environment all incoming requests are routed to the green environment - the blue one is now idle.
Blue-green deployment provides a rapid way to rollback - if anything goes wrong traffic is routed back to the blue environment.
An advantage of this approach is that it allows the disaster-recovery procedure to be tested on every software release. This goes a significant way to eliminating release management as a contributor to systems instability.
Infrastructure as code
One of the most insidious things in IT that leads to systems instability is Configuration Drift. Configuration drift is the phenomenon where servers in an infrastructure become more and more different from one another as time goes on, due to manual ad-hoc changes and updates, and general entropy. Configuration drift is almost impossible to avoid where servers are deployed and changes made to them via manual process. Often times, high-availability (HA) clusters and disaster recovery (DR) environments fail to work as designed because over time changes made to the production environment are not accurately replicated into the HA and DR environments.
The emerging, and most effective way, to treat this problem is via a practice called Infrastructure as Code (IaC). IaC is an approach to infrastructure automation based on practices from software development. It emphasises consistent, repeatable routines for provisioning and changing systems and their configuration. In practice this means writing software code to manage configurations and automate provisioning of infrastructure to ensure these actions are thoroughly tested before being applied to business critical systems.
IaC involves using tested and proven software development practices that are already being used in application development. e.g.,: version control, testing, small deployments, continuous integration, use of design patterns etc. The major benefit of Infrastructure as Code is to be able to easily and responsibly manage changes to infrastructure. The introduction of `IaC practices requires the infrastructure team to acquire/enhance software development skills and, in time, changes the profile of infrastructure teams from administrators to software engineers.
Using IaC the IT infrastructure supports and enables change, rather than being an obstacle or a constraint for its users. Changes to the system are routine, without drama or stress for users or IT staff and IT staff spends their time on valuable things which engage their abilities, not on routine, repetitive tasks. Teams are able to easily and quickly recover from failures, rather than assuming failure can be completely prevented and improvements are made continuously, rather than done through expensive and risky “big bang” projects.
Infrastructure as code practices found their roots in the “built for the web” organizations such as Google, Amazon and Facebook but, over the last 18-24 months, have started to gain a foothold in more traditional IT organizations world-wide
Microservices
As technology has progressed over the last decade, we’ve seen an evolution from monolithic architectures to service oriented architectures (SOA) and now to microservice based architectures. Most of the legacy applications in the Bank fall into the monolithic category; the ones developed over the last decade were mostly architected for modularity and reuse (SOA) and we are, for the first time, now building applications using microservices architecture patterns.
The term "Microservice" has sprung up over the last few years to describe a particular way of designing software applications as suites of independently deployable services.
Microservice architectural style is an approach to developing a single application as a suite of small services. These services are built around business capabilities and independently deployable by fully automated deployment machinery.
The philosophy of the microservices architecture essentially equals to "Do one thing and do it well” and can be described as follows:
- The services are small - fine-grained to perform a single function.
- The organization culture should embrace automation of testing and deployment.
- This eases the burden on management and operations and allows for different development teams to work on independently deployable units of code.
- The culture and design principles should embrace failure and faults, similar to anti-fragile systems.
- Each service is elastic, resilient, composable, minimal, and complete.
When done well, Microservices are highly decoupled and built for failure, thus they can cope with failure and outages. This isolation of simple small services makes them independent from each other, so that when one fails the others don’t stop working. They are explicitly built to expect failure. Through this decoupling applications become more resilient and can better cope with change and disruptions - all this while keeping agility and speed in the development process.
Application programming interfaces (APIs)
In the simplest terms, APIs are sets of requirements that govern how one application can talk to another. APIs do all this by “exposing” some of a program’s internal functions to the outside world in a limited fashion.
This makes it possible for applications to share data and take actions on one another’s behalf without requiring developers to share all of their software’s code. APIs allow one piece of software to make use of the functionality of, or data available to, another. By enabling data sharing between internal IT systems and between one organisation and another, APIs facilitate not only the dissemination of knowledge but also the design of innovative online services.
Application Programming Interfaces (APIs) are the foundation on which the digital economy is built. APIs enable a business to expose content or services to internal or external audiences.
By exposing services such as payments and statements to the market via public-facing (external) APIs it will be possible for 3rd parties such as Fintech’s to consume these banking services and make them available to their customers.
The use of private (internal to an organization) APIs can enhance system stability by removing tight coupling between systems by allowing program-to-program communication only to take place through a defined, measured and supported method. Today there are many ways for applications to communicate with each other, some of which are vulnerable to the changing internal structures of the applications. Used correctly, APIs abstract these changes and protect the “calling” application from changes the API provider may be making to its internal application structures. This better isolates systems from each other, leading to improved reliability and resilience.
Bibliography
While this is not an exhaustive list, there are a number of sources that have been drawn on for inspiration in the compilation of this and the subsequent posts. Some of the content has been used verbatim, some quoted and others used simply to frame and argument or position.
Books
- Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation. Jez Humble and David Farley
- Infrastructure as Code: Managing Servers in the Cloud. Kief Morris
- Effective DevOps: Building a Culture of Collaboration, Affinity, and Tooling at Scale. Jennifer Davies and Katherine Daniels
- Work Rules!: Insights from Inside Google That Will Transform How You Live and Lead. Laszlo Bock
- Deep Work: Rules for Focused Success in a Distracted World. Cal Newport
- The Field Guide to Understanding Human Error. Sidney Dekker
- Just Culture: Balancing Safety and Accountability. Sidney Decker
- Release IT. Design and Deploy Production Ready Software: Michael T. Nygard
- The Principles of Product Development Flow. Donald G. Reinertsen
- The Open Organization. Igniting Passion and Performance. Jim Whitehurst and Gary Hamel
- Team of Teams: New Rules of Engagement for a Complex World. General Stanley McChrystal and David Silverman
- DevOps Hiring. Dave Zwieback
- The Human side of Post Mortems. Managing Stress and Cognitive Biases. Dave Zwieback
- Antifragile Systems and Teams. Dave Zwieback
- Building Great Software Engineering Teams. Josh Tyler
- Debugging Teams. Better Productivity Through Collaboration. Brian Fitzpatrick & Ben Collins-Sussman
Online Papers & Blogs
- How Complex Systems fail. Richard I. Cook MD
- Continuous software engineering: A roadmap and agenda. Brian Fitzgerald, Klaas-Jan Stol
- Infrastructure As Code, The Missing Element In The I&O Agenda. Robert Stroud
- #NoProjects. Shane Hastie
- Put developers On The Front Lines Of app support. Kurt Bittner, Eveline oehrlich, Christopher Mines and Dominique Whittaker
- Agile Manifesto
- KitchenSoap (Johan Allspaw)
- Martin Fowler
- Systems Blindness: The Illusion of Understanding (Daniel Goleman)
This was a guest post by Mike Murphy. Mike is the Chief Technology Officer of the Standard Bank Group. You can also listen to a podcast featuring Mike by clicking here.



Very interesting piece!
Agile manifesto principle says “Working software is the primary measure of progress”, I would add that: Today, 2017, with more efficient concepts such as Microservices and uber-jar at play, “Secure software is the primary measure of progress”. It is no longer enough to have “working/functional software”. working software that does not protect the users from a breach of confidentiality or compromise of integrity is just not fit for today’s world.
Just this August, a backdoor was embedded into one of the code libraries used by a major financial services software – NetSarang software (nssock2.dll). now, this backdoor was existing in the Software build for 3 weeks (July 17 –August 4), whilst it was a “functionally working software” and passed the CI build checks, Security was lacking in that particular build. Suffice to say that this is a common occurrence in Dev where Security is lacking. This begs the question: How do you handle the distribution chain in an SDLC so that Security isn’t lacking? And the example further emphasises that when we automate the DevOps process, we should always try to inculcate Security into DevOps, so much so that before we pass the software build for release, we are sure that Security has been passed as well.
Lesson here: Features/ Functionality minus Security = Disaster